前言
最近在工作中遇到各种要处理Excel文件的问题, 所以每次都会自己写个python脚本来自动化处理各种Excel, 所以在此记录一下
案例
一,案例1
对比2个Excel的不同,将不同的地方标记成黄色,并生成2个Excel结果文件来展示黄色不同的地方.
代码片段
workbook1 = pxl.load_workbook(r"/Users/luochuan/Desktop/用Python对比2个Excel的不同/Resume_Louis.Luo_Test1.xlsx")
workbook2 = pxl.load_workbook(r"/Users/luochuan/Desktop/用Python对比2个Excel的不同/Resume_Louis.Luo_test2.xlsx")
......
workbook1_sheet1 = workbook1['sheet']
workbook2_sheet1 = workbook2['sheet']
for i in range(1, (max_row + 1)):
for j in range(1, (max_column +1)):
cell_1 = workbook1_sheet1.cell(i, j)
cell_2 = workbook2_sheet1.cell(i, j)
if cell_1.value != cell_2.value:
cell_1.fill = PatternFill("solid", fgColor='FFFF00')
cell_1.font = Font(color=colors.BLACK, bold=True)
cell_2.fill = PatternFill("solid", fgColor='FFFF00')
cell_2.font = Font(color=colors.BLACK, bold=True)
workbook1.save(r'result1.xlsx')
workbook2.save(r'result2.xlsx')
效果显示:(已将2个excel的不同之处用黄色显示)
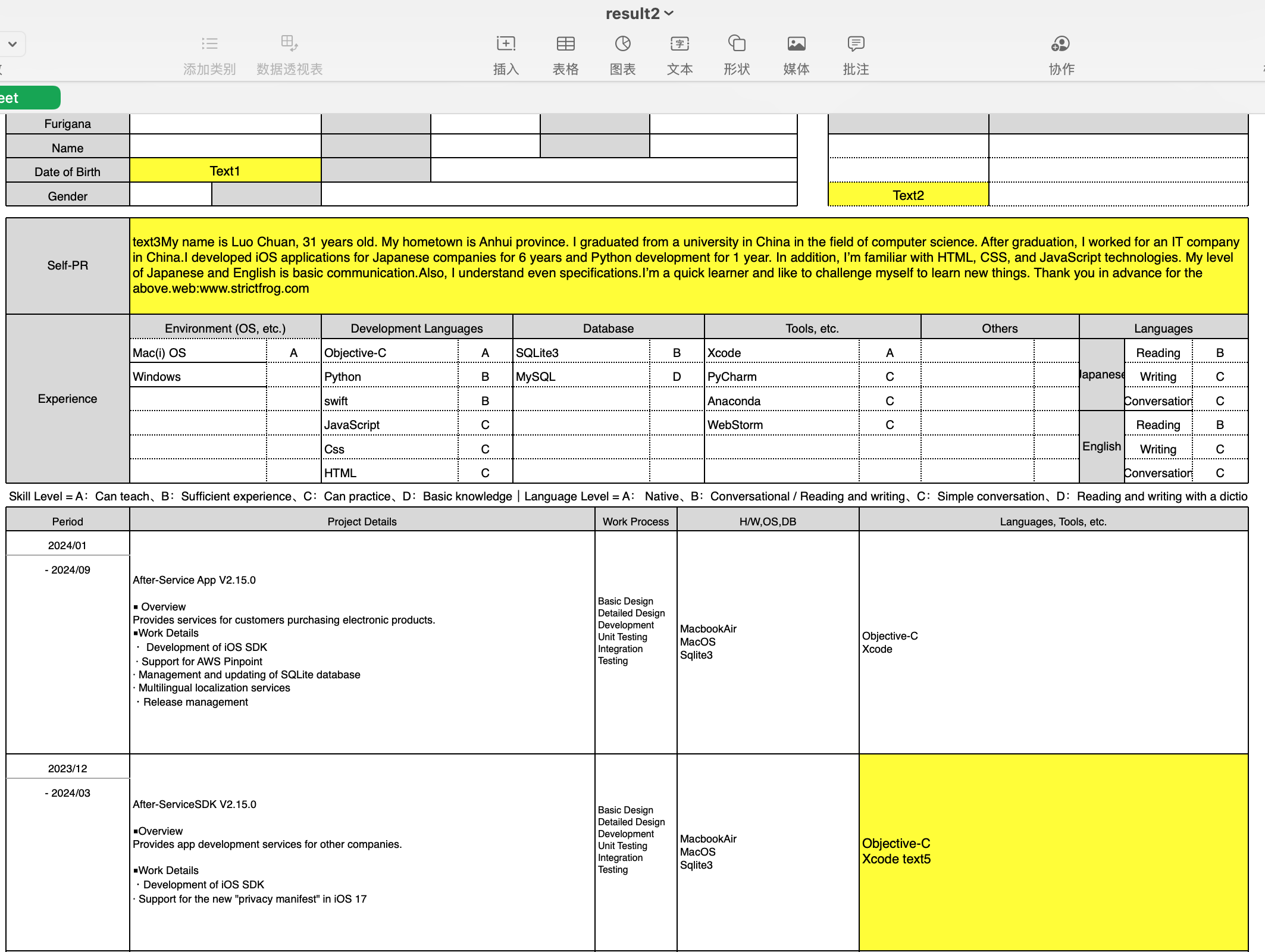
详细代码及测试数据已上传到GitHub用Python对比2个Excel的不同
二,案例2
Excel的某一列包含多个值, 这些值使用空格,斜杠,等等被隔开. 要求将这些值单独拆成多行.
代码片段
splitString = "\n"
for i in range(1, (workbook1_sheet1.max_row)):
value = workbook1_sheet1.cell(i, 3).value
if value != None:
list = value.split(splitString)
if len(list) > 1:
workbook1_sheet1.cell(i, 3).value = list[0]
workbook1_sheet1.insert_rows(idx=(i+1), amount= (len(list)-1))
for j in range(1, len(list)):
for col in range(1, workbook1_sheet1.max_column+1):
cell = workbook1_sheet1.cell(i, column = col)
targetCell = workbook1_sheet1.cell(row=(i+j), column=col)
if col == 3:
targetCell.value = list[j]
else:
targetCell.value = cell.value
# targetCell.fill=PatternFill("solid", fgColor='FFFF00')
targetCell.font = Font(color=colors.BLACK, bold=False, size=16)
效果显示:(已将某一列中数据按照空格分割成多行数据)
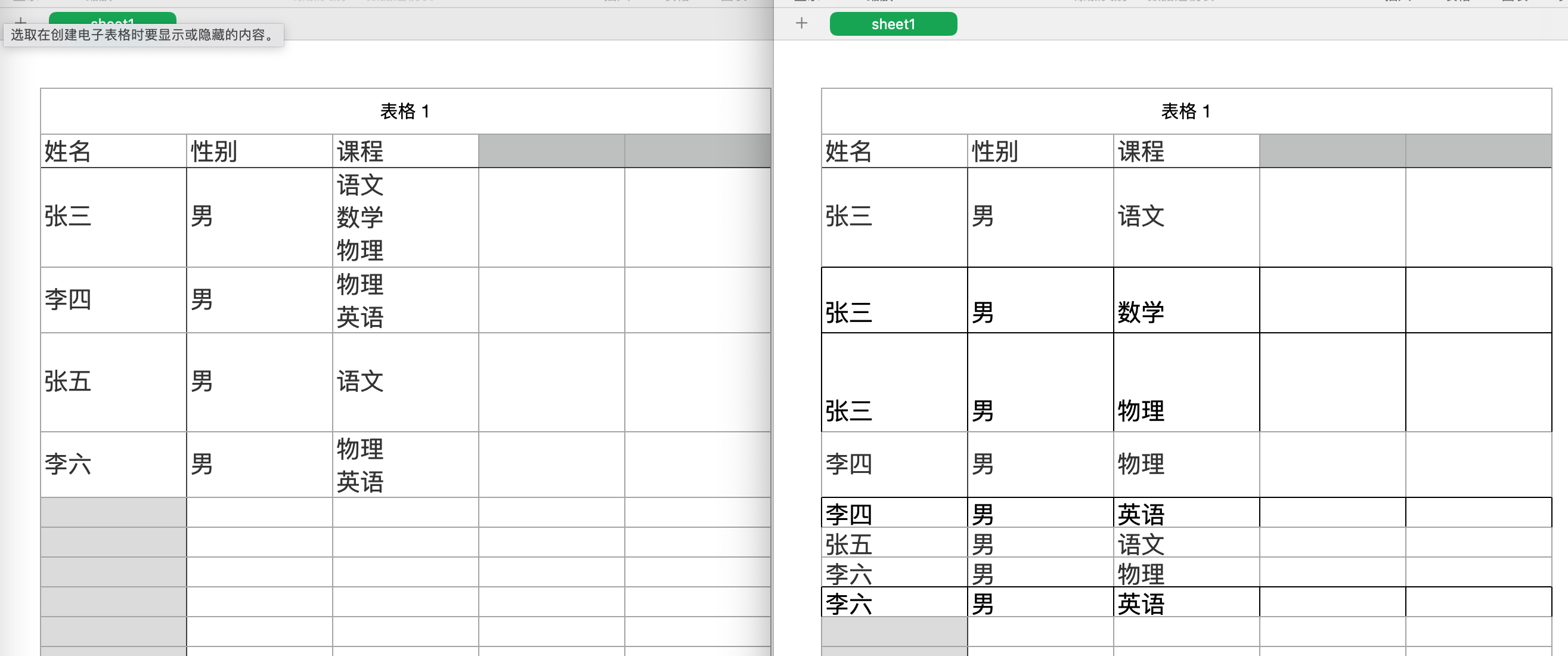
详细代码及测试数据已上传到GitHubsplitColumn
二,案例3
修改csv中的空值, 修改规则:参照映射excel.
代码片段
# 获取映射表数据(rules.xlsx)
ruleList = []
for i in range(1, (workBook1_sheet.max_row +1)):
nameStr = workBook1_sheet.cell(i, 1).value
ageStr = workBook1_sheet.cell(i, 2).value
idStr = workBook1_sheet.cell(i, 3).value
if len(idStr) > 0:
ruleOneList = [nameStr,ageStr,idStr]
ruleList.append(ruleOneList)
# 读取源数据(testData.csv) 并且根据映射表数据规则 修改源数据
rows = []
with open(csvFileName, 'r', newline='', encoding='utf-8') as f:
rows = [row for row in csv.DictReader(f)]
for i in range(0, len(rows)):
if rows[i]['Id'] == "Null":
for j in range(0, len(ruleList)):
if rows[i]['Name'] == str(ruleList[j][0]) and rows[i]['Age'] == str(ruleList[j][1]) :
rows[i]['Id'] = str(ruleList[j][2])
f.close
# 将修改后的源数据写入源数据文件中
header = rows[0].keys()
with open(csvFileName, 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
writer.writerows(rows)
f.close
效果显示:(将testData.csv某一列的为Null的数据, 在rultes.xlsx中查找对应正确的数据,修改testData.csv)

详细代码及测试数据已上传到GitHubchangeForCsv
关于作者
我是Louis,一名长期从事iOS与AI相关工程实践的工程师,也是一个正在探索产品与商业可能性的准创始人.
这里的文章,更多是我在项目中用过,踩过坑,反复验证过的东西,而不是为了流量而写的“快内容”.
☕ 打赏
如果这篇文章对你有帮助,欢迎请我喝一杯咖啡☕️
GitHub Sponsors(推荐)You can support my work via PayPay by searching my PayPay ID:
PayPay ID: luochuan


你的支持会让我有更多时间,把真实项目中的经验持续整理和分享出来.
不打赏也完全没关系,感谢你读到这里.
联系与合作
如果你:
· 正在做iOS App / AI / 自动化相关的项目
· 对技术选型、架构设计、产品落地有困惑
· 或希望进行技术交流、合作探讨
欢迎通过以下方式联系我: