背景
ファイル解析用のChatAgentを開発する際に、多ターン対話のシナリオでユーザーがファイルをアップロードして解析し、LLMがそのファイル解析結果に基づいてユーザーの質問に回答します。 しかしユーザーの2回目、3回目、4回目…の質問では、質問がファイルと全く関係ない場合があります。この場合、プロンプトのコンテキストに常にファイルの解析結果を含めるのは適切ではなくなります。なぜならトークン入力が多すぎてコストが高くなるためです。プロンプトコンテキストの管理とフィルタリングが非常に重要になります。
分析
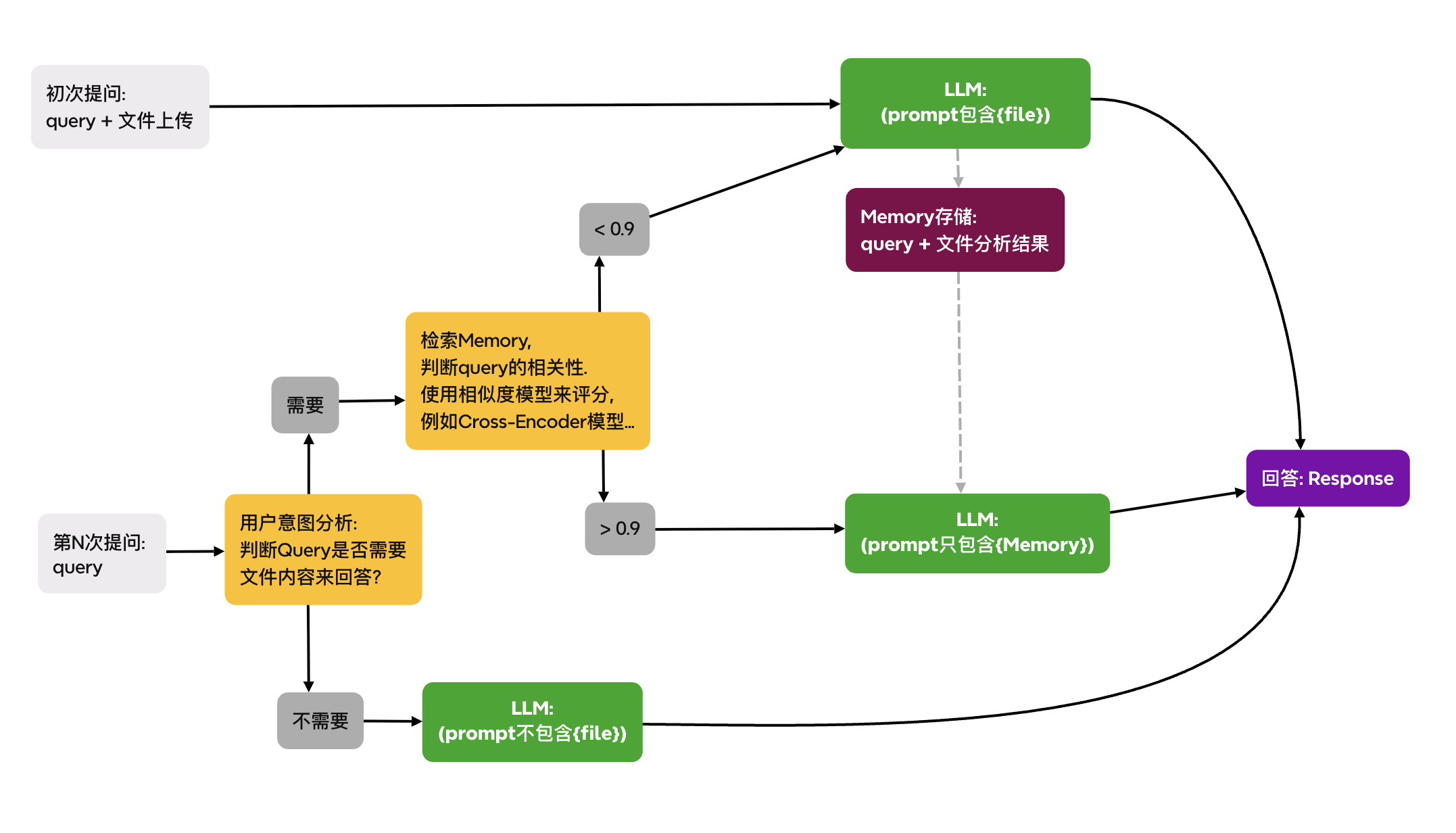
- 最終的な結果品質は、ユーザーの各質問に応じてプロンプトコンテキストの構造と長さを動的に管理することに依存します。
- ユーザーの各質問に応じてプロンプトコンテキストの構造と長さを動的に管理するには、ユーザーの質問の意図を解析し、ファイルを再度解析するかどうかを判断する必要があります。
- 意図解析の結果、ユーザーの質問がファイルと全く関係ない場合、ファイル解析結果を含まないように動的にプロンプトコンテキストを構成できます。
- 意図解析の結果、ユーザーの質問が初回のファイル解析時の質問とほぼ同じであれば、前回のファイル解析結果を直接用いて回答すればよいです。ここでは「質問<=>結果」の関連度スコアが関係します。
- 意図解析の結果、ユーザーの質問は初回のファイル解析時の質問とは異なるが、ファイル内容をもとに回答する必要がある場合は、LLMを使って再度ファイルを解析します。
フローチャート
关于作者
我是Louis,一名长期从事iOS与AI相关工程实践的工程师,也是一个正在探索产品与商业可能性的准创始人.
这里的文章,更多是我在项目中用过,踩过坑,反复验证过的东西,而不是为了流量而写的“快内容”.
☕ 打赏
如果这篇文章对你有帮助,欢迎请我喝一杯咖啡☕️
GitHub Sponsors(推荐)
PayPay
You can support my work via PayPay by searching my PayPay ID:
PayPay ID: luochuan
微信支付

支付宝

你的支持会让我有更多时间,把真实项目中的经验持续整理和分享出来.
不打赏也完全没关系,感谢你读到这里.
联系与合作
如果你:
· 正在做iOS App / AI / 自动化相关的项目
· 对技术选型、架构设计、产品落地有困惑
· 或希望进行技术交流、合作探讨
欢迎通过以下邮箱联系我:
luochuanad@gmail.com