背景
複雑なRAG設計なしに、LlamaIndexのReAct RAG Agentフレームワークを使って財務諸表の分析を行うだけで、初級のビジネスアナリストと同レベルの成果が得られます。しかし、多くの制限もあります。個人的には、小規模な企業向けに適していると考えています。
財務分析構造図
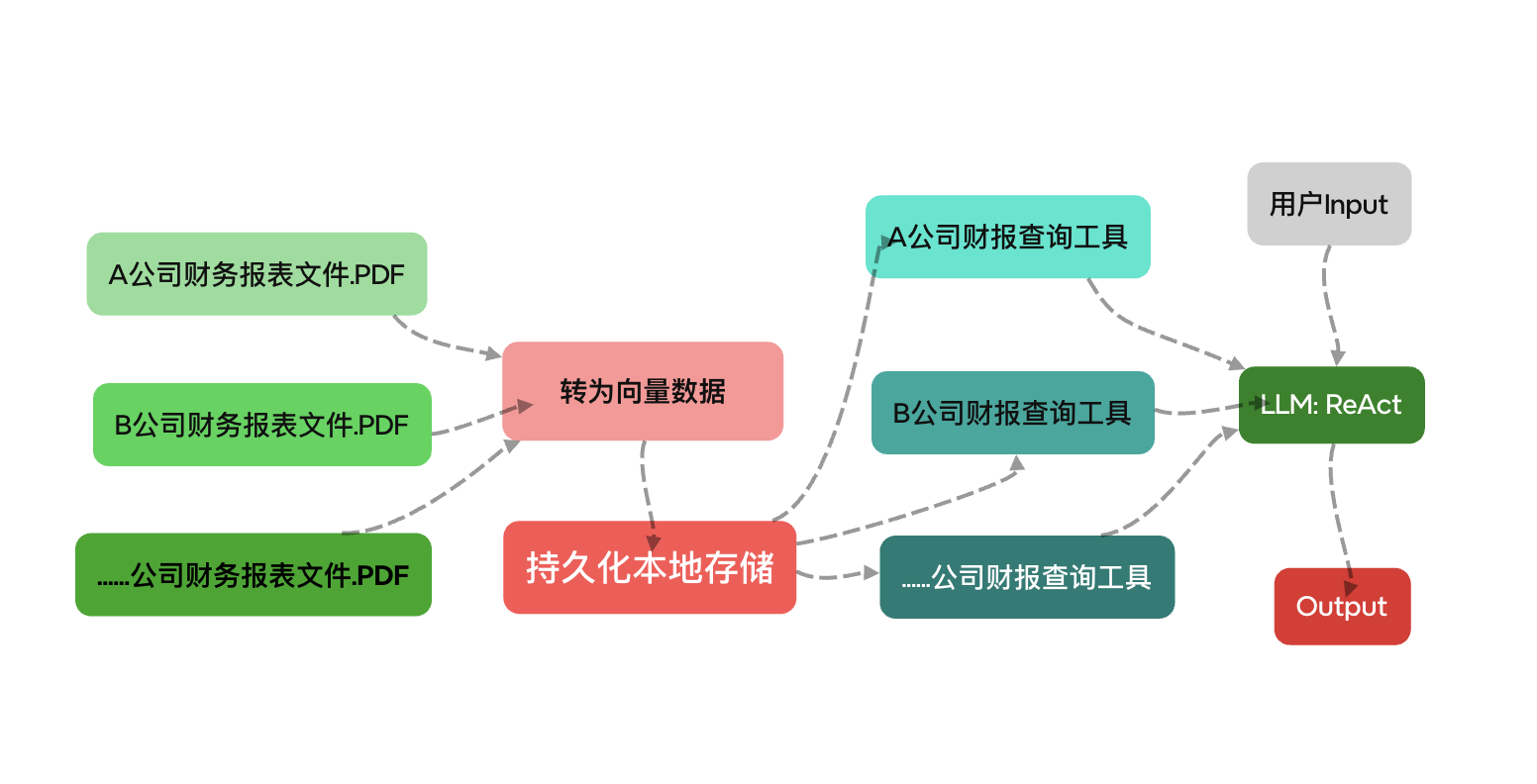
1. A社、B社などの財務諸表ファイルの読み込み
from llama_index.core import SimpleDirectoryReader
A_doc = SimpleDirectoryReader(
imput_file = ["./A会社財務諸表ファイル_2025.pdf"]
).load_data()
......
2. 財務データに基づいてベクトルデータを生成しローカルに保存
from llama_index.core import VectorStoreIndex
A_index = VectorStoreIndex.frome_documents(A_doc)
......
frome llama_index.core import StorageContext
A_index.storage_context.persist(persist_dir="./storage/A")
......
ローカルのベクトルデータのディレクトリ構成:
A
|- default_vectory_store.json
|- docstore.json
|- graph_store.json
|- image_vectore_store.json
|- index_store.json
B
|- default_vectory_store.json
|- docstore.json
|- graph_store.json
|- image_vectore_store.json
|- index_store.json
......
3. クエリツールの設定:(A/B/……)
from llama_index.core.tools import QueryEngineerTool, ToolMetadata
query_engineer_tools= [
QueryEngineerTool(
query_engineer = A_engineer,
metadata = ToolMetadata(
name = "A_finance",
description= ("A社の財務諸表情報を提供するためのツール"),
),
),
......
]
4. LLMの作成:ReAct RAG Agent
from llama_index.core.agent import ReActAgent
agent = ReActAgent.from_tools(query_tools, llm=llm, verbose=True)
考察:(ReAct RAG Agent)
メリット:
1. 会社の財務諸表ファイルを提供するだけで良い
2. シンプルかつ迅速で、既存のLlamaIndexを使ってすぐにReAct RAG Agentを構築できる
3. 分析結果は初級ビジネスアナリストのレベルに達している
デメリット:
1. RAGプロセスの詳細設計がなく、LlamaIndex本体の能力に依存している
2. ReActプロセスの設計がなく、同様にLlamaIndexの能力に依存している
3. 大規模モデルのファインチューニングがされていないため、分析結果が初級レベルに留まる
4. 人間の思考ポイントが組み込まれておらず、最大限の知的活用:AI+人を実現できていない
この4つの課題をクリアすれば、トップクラスのビジネスアナリストのレベルに到達します。この点に基づき、私は今後のAIの発展と応用に大きな期待を持っています。 なぜなら、このようなシステムの開発は最長でも半年で、トップビジネスアナリストが20年かけて得た経験に匹敵する能力を達成できるからです。これは人類最大のレバレッジとなります。
参考文献
記事の例は『動手做AI Agent』著者:黄佳 より引用しています。
关于作者
我是Louis,一名长期从事iOS与AI相关工程实践的工程师,也是一个正在探索产品与商业可能性的准创始人.
这里的文章,更多是我在项目中用过,踩过坑,反复验证过的东西,而不是为了流量而写的“快内容”.
☕ 打赏
如果这篇文章对你有帮助,欢迎请我喝一杯咖啡☕️
GitHub Sponsors(推荐)You can support my work via PayPay by searching my PayPay ID:
PayPay ID: luochuan


你的支持会让我有更多时间,把真实项目中的经验持续整理和分享出来.
不打赏也完全没关系,感谢你读到这里.
联系与合作
如果你:
· 正在做iOS App / AI / 自动化相关的项目
· 对技术选型、架构设计、产品落地有困惑
· 或希望进行技术交流、合作探讨
欢迎通过以下邮箱联系我:
luochuanad@gmail.com